1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
import requests
from lxml import etree
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4643.2 Safari/537.36"
}
proxy = {
"http": "114.98.114.19:3256",
"http": "211.65.197.93:80"
}
def spyder_1(url):
response = requests.get(url, headers=headers, proxies=proxy)
text = response.content.decode("UTF-8", "ignore")
html = etree.HTML(text)
detail_xpath_str = "//ul[@class='rank-list']//li[@class='rank-item']//div[@class='info']"
video_title = html.xpath(detail_xpath_str + "//a[@class='title']/text()")
playtimes_n_barrage = html.xpath(detail_xpath_str + "//span[@class='data-box']/text()")
playtimes_n_barrage = [x.strip() for x in playtimes_n_barrage]
video_playtimes = playtimes_n_barrage[::2]
video_barrage = playtimes_n_barrage[1::2]
video_up_name = html.xpath(detail_xpath_str + "//span[@class='data-box up-name']/text()")
video_up_name = [x.strip() for x in video_up_name]
video_href = html.xpath(detail_xpath_str + "/a/@href")
video_href = [x.replace("//", "") for x in video_href]
video_BV = [x.replace("www.bilibili.com/video/", "") for x in video_href]
video_score = html.xpath(detail_xpath_str + "//div[@class='pts']/div/text()")
video_info_1 = {
"标题": video_title,
"播放量": video_playtimes,
"弹幕量": video_barrage,
"up主": video_up_name,
"视频链接": video_href,
"BV号": video_BV,
"排行榜综合得分": video_score
}
return video_info_1
def spyder_2(url):
response = requests.get(url, headers=headers, proxies=proxy)
text = response.content.decode("UTF-8", "ignore")
html = etree.HTML(text)
detail_xpath_str = "//ul[@class='rank-list pgc-list']//li[@class='rank-item']//div[@class='info']"
video_title = html.xpath(detail_xpath_str + "//a[@class='title']/text()")
playtimes_n_barrage_n_like = html.xpath(detail_xpath_str + "//span[@class='data-box']/text()")
playtimes_n_barrage_n_like = [x.strip() for x in playtimes_n_barrage_n_like]
video_playtimes = playtimes_n_barrage_n_like[::3]
video_barrage = playtimes_n_barrage_n_like[1::3]
video_like = playtimes_n_barrage_n_like[2::3]
video_href = html.xpath(detail_xpath_str + "/a/@href")
video_href = [x.replace("//", "") for x in video_href]
video_score = html.xpath(detail_xpath_str + "//div[@class='pts']/div/text()")
video_info_2 = {
"标题": video_title,
"播放量": video_playtimes,
"弹幕量": video_barrage,
"追番": video_like,
"视频链接": video_href,
"排行榜综合得分": video_score
}
return video_info_2
if __name__ == '__main__':
classify_1 = {
"全部": "all",
"国创相关": "guochuang",
"动画": "douga",
"音乐": "music",
"舞蹈": "dance",
"游戏": "game",
"知识": "knowledge",
"科技": "tech",
"运动": "sports",
"汽车": "car",
"生活": "life",
"美食": "food",
"动物圈": "animal",
"鬼畜": "kichiku",
"时尚": "fashion",
"娱乐": "ent",
"影视": "cinephile",
"原创": "origin",
"新人": "rookie"
}
classify_2 = {
"番剧": "bangumi",
"国产动画": "guochan",
"纪录片": "documentary",
"电影": "movie",
"电视剧": "tv"
}
url_raw = "https://www.bilibili.com/v/popular/rank/"
excel = pd.ExcelWriter(r'C:\Users\ASUS\Desktop\output.xlsx')
for j, i in classify_1.items():
url = url_raw + i
video_info_1 = spyder_1(url)
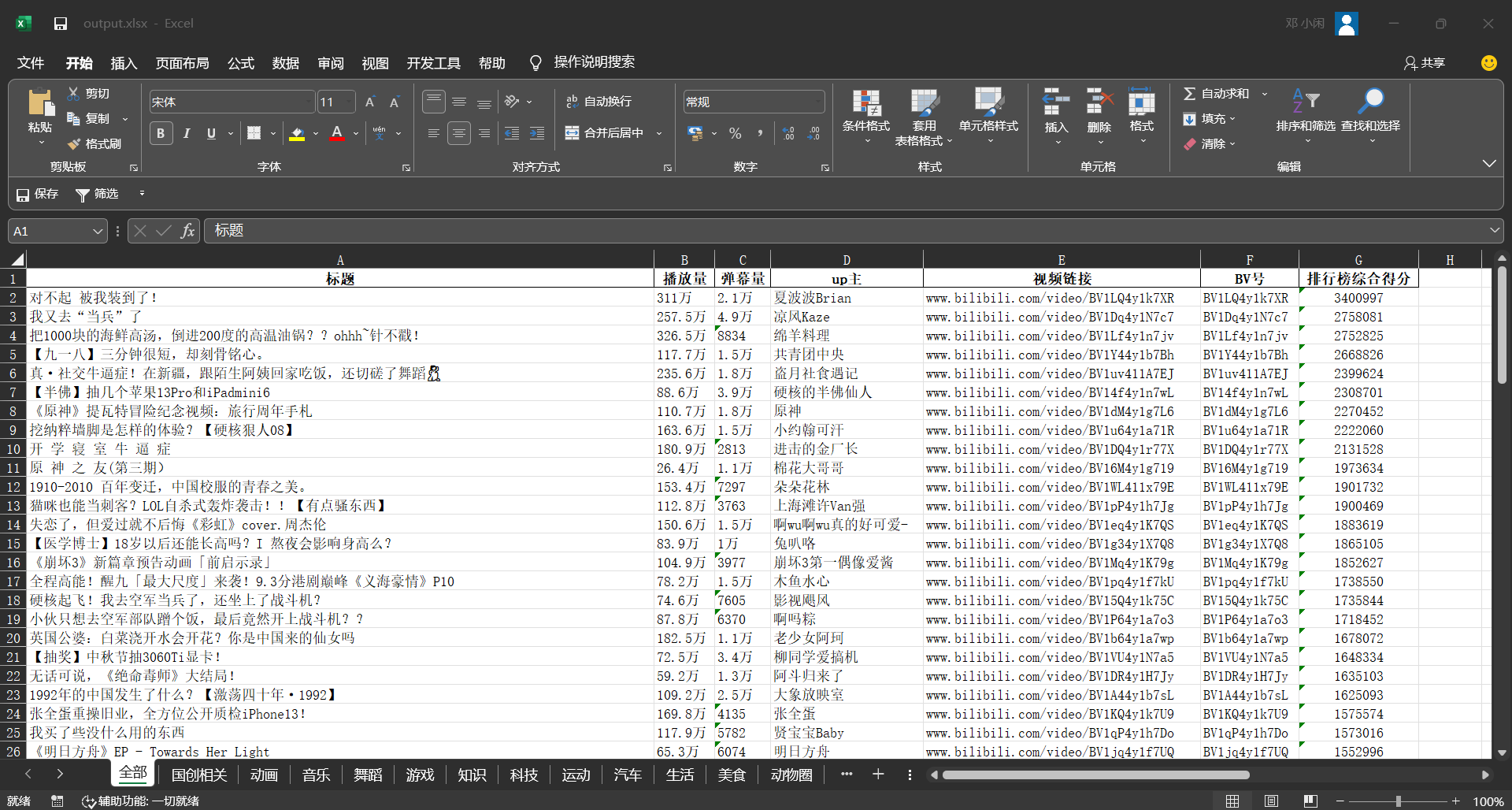
df = pd.DataFrame(video_info_1)
df.to_excel(excel, sheet_name=j, index=False)
print("\n", "=" * 50, j, "分区排行榜视频信息已经成功爬取!", "=" * 50, "\n")
for j, i in classify_2.items():
url = url_raw + i
video_info_2 = spyder_2(url)
df = pd.DataFrame(video_info_2)
df.to_excel(excel, sheet_name=j, index=False)
print("\n", "=" * 50, j, "分区排行榜视频信息已经成功爬取!", "=" * 50, "\n")
excel.save()
|
 微信
微信 支付宝
支付宝




